


Next: Gradient Calculation: Constrained Optimization
Up: Review of The Basics:
Previous: Constrained Optimization
The convergence rate for the steepest descent method is connected to
the eigenvalues of the Hessian, in particular, to the ratio of the smallest
eigenvalue to the largest one. We discuss this in some details in this section.
A basic gradient descent method has the form
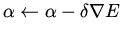 |
|
|
(19) |
where 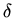 is a step size, whose magnitude is determined using
a line search.
At the a vicinity of a minimum
is a step size, whose magnitude is determined using
a line search.
At the a vicinity of a minimum
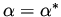 , since
, since
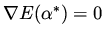 , we have
, we have
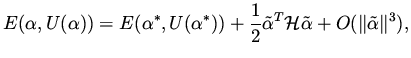 |
|
|
(20) |
where
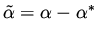 .
From this we see that
the gradient in the vicinity of the minimum can be expressed as
.
From this we see that
the gradient in the vicinity of the minimum can be expressed as
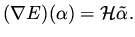 |
|
|
(21) |
Substituting the last equality into (19) and
subtracting 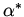 from both sides we get,
from both sides we get,
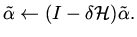 |
|
|
(22) |
This relation expresses the new errors (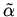 on left) as a
function of the old errors ( on right).
Convergence rate depends on
on left) as a
function of the old errors ( on right).
Convergence rate depends on
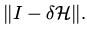 |
|
|
(23) |
Now we want to relate the difficulty in solving an optimization problem
using the steepest descent method to the
condition number of the Hessian.
The Hessian is a symmetric matrix and it is also positive definite
(if indeed we have a minimum). Let its eigenvalues be 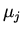 with eigenvectors
with eigenvectors 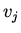 , i.e.,
, i.e.,
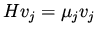 |
|
|
(24) |
and assume that
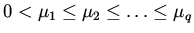 .
The iteration matrix was shown to be
.
The iteration matrix was shown to be
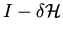 and its
eigenvalues are
and its
eigenvalues are
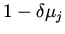 . For convergence we need
. For convergence we need
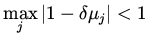 |
|
|
(25) |
which implies
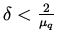 .
Taking
.
Taking
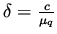 , with
, with 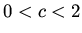 gives
gives
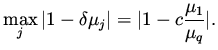 |
|
|
(26) |
Thus, the convergence rate depends on the ratio of the smallest to the
largest eigenvalue of the Hessian. When dealing with symmetric
positive matrices this is the condition number of the matrix.
The structure of the minimum is essentially determined by 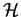 and its
analysis in the context of fluid dynamics equation will be demonstrated
later. It plays a major role in the optimization problem and its solution
processes.
and its
analysis in the context of fluid dynamics equation will be demonstrated
later. It plays a major role in the optimization problem and its solution
processes.
Several approaches for calculating gradients of 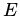 subject to the constraints
exist, and we discuss some of them.
subject to the constraints
exist, and we discuss some of them.
Next: Gradient Calculation: Constrained Optimization
Up: Review of The Basics:
Previous: Constrained Optimization
Shlomo Ta'asan
2001-08-22