<PREV>
<INDEX> <NEXT>
Massively
Parallel Computers - GPU Computing
Hardware architecture (Nvidia, AMD)
fpg1.math - 2 x NVIDIA GeForce
GTX 1080 Ti (Pascal):
- 3584 CUDA Shaders, Core clock 1480MHz, Clock Shaders
1582MHz
- 11GB GDDR5X RAM, Clock RAM
1376 MHz (11008 MHz effective), Bus RAM 352 bit
- Power 250W, Computing power SP 11.34TFlops
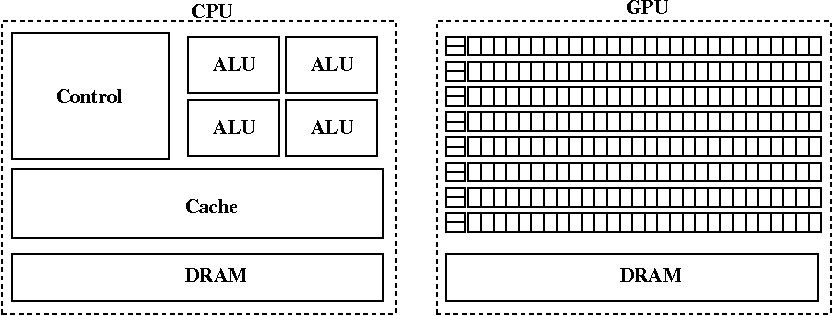
GPU architecture:
Streaming Processors (SP): share control logic and instruction
cache ->
Streaming Multiplocessors (SM) ->
building block
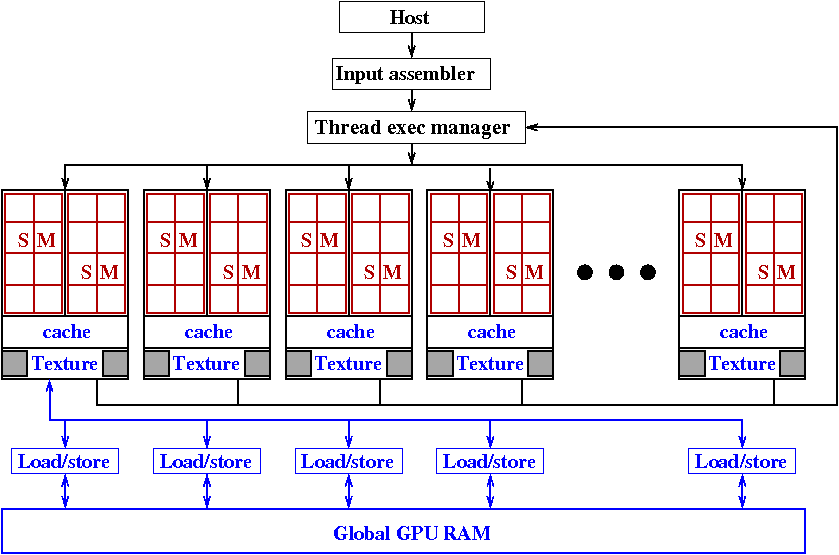
GPU RAM is different from system
RAM: memory not shared between system and GPU
Software
- code: CPU code + GPU kernel
- development environment:
- CUDA (for NVIDIA GPUs) - Compute
Unified Device Architecture - extension to C
- OpenCL (open standard: Intel , AMD, NVIDIA, ARM) - based on C99
- OpenACC - high level
directives but narrower application
- wrappers in Python, Perl, Fortran, Java,
Ruby, Lua, Haskell, MATLAB, IDL
- native support in
Mathematica
- Machine Learning: Python +
cuDNN + TensorFlow
- driver
Programming
CUDA:
- extension to C
- SPMD
- no GPU needed for development
(emulated GPU)
- components:
- driver: system; libraries
and modules for kernel, xorg
- compiler,
headers, libraries: system (/usr/local/cuda)
- samples:
/usr/local/cuda/samples
Steps:
- Identify the part suitable for
GPU computing
- Isolate the data
- Transfer the data to GPU:
cudaMalloc(),
cudaMemcpy()
- Describe kernel function:
1grid -> 3D array of blocks -> 3D array of threads
- __global__, __device__,
__host__
- threadIdx.x, threadIdx.y, blockIdx, blockDim, gridDim
- Launch GPU kernel -> grid
of threads: function<<<exec
parameters>>>(arguments)
- Transfer the results back to
CPU memory: cudaFree(),
cudaMemcpy()
- Repeat as needed
Memory model:
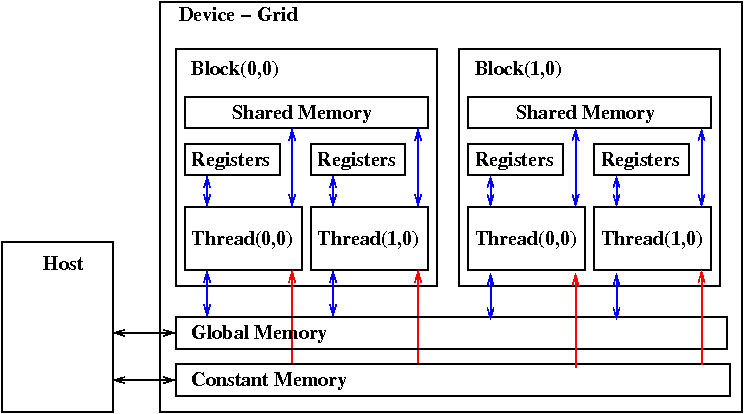
Compile and execute
c++ -c -> get the
objects
nvcc -O -> compile the device kernel
c++ -> final binary
<PREV> <INDEX>
<NEXT>