Problem
definition
Find
groups of 2 or more consecutive characters (as many as possible,
including spaces or symbols) which can be found in at least
60% of the entries in a column of a csv file.
as many as possible --
characters? groups?
Matching substrings in column
'018am_19pm_dist': ['m dist', ' d', 'pm', 'pm di', 'am ', 'pm
dis', 'ist', 'st', '
di', 'dis', 'dist', 'm 1', 'm dis', ' dis', 'is', 'm di', 'pm
d', 'di', 'am', 'pm ', 'm d', ' dist', 'm ', 'am 1', ' 1', 'pm
dist']
-vs-
Matching substrings in column
'018am_19pm_dist': [ 'am 1', 'pm dist']
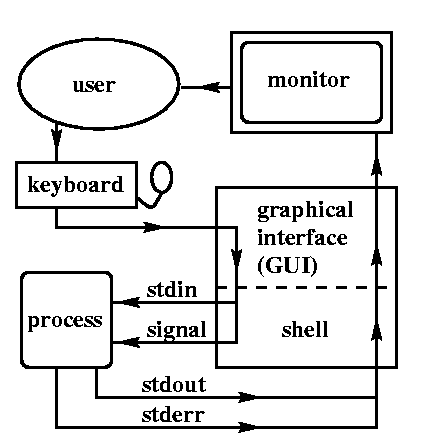
User
communication
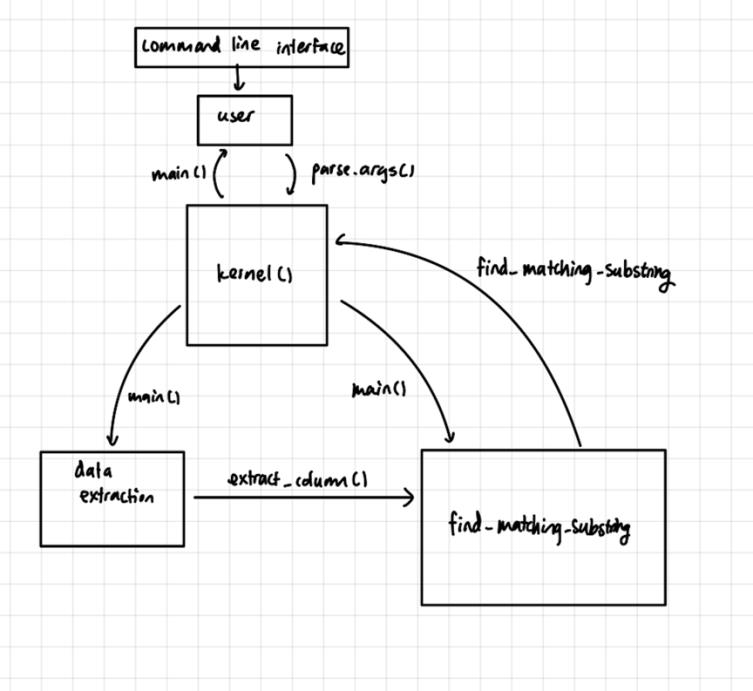
API description
find_matching_substrings()
function takes a column of data and performs the core
algorithmic work of searching for matching substrings
according to specified criteria. It iterates over the column
data until all possible matches are found. The results are
then prepared for handoff back to the Kernel module.
find_matching_substrings(column,
min_length=2, match_percentage=60, greedy_match=0)
column - name of column
min_length=2 - min matching substring length
(default = 2)
match_percentage - min match percentage (default =
60%)
greedy_match=0 - detect only the longer matches
(greedy_match = 1) or all submatches (default)
Interface between the user and the script
no more than one free floating argument (two here)
make the script executable and named meaningfully
chmod a+x kernel.py
ln -s kernel.py SearchSubstring
#!/usr/bin/python3
<-- on top